1. Introduction and Objectives
Profile Assist is a Java-based project that provides AI-supported assistance for matching profiles with job postings and adapting profiles accordingly. The goal is to develop an open, maintainable, and testable software solution that combines modern Java technologies and AI components.
1.1. Background
-
Developed as an internal open-source project by a group of developers.
-
Focus on the use of AI to create and test synthetic test data, use of personas such as “full-stack developer,” “DevOps engineer,” with suitable and unsuitable matches, etc.
-
The project is open to all interested developers (including non-Java natives) on a voluntary basis.
1.2. Project goals
-
Creation of an AI-based assistance system to support profile creation and testing.
-
Promotion of best practices in architecture, coding, and review processes within the developer group.
1.3. Quality goals
-
High test coverage (80% branch coverage, including component integration tests).
-
Readable, maintainable, and standards-compliant code (in accordance with code guidelines and language rules).
-
Secure handling of data (synthetic test data, no real data without review).
-
Efficient code reviews and release processes.
1.4. Stakeholders
| Role | Description | Goal/Intention | Contact | Priority/Acceptance Relevance | Information Need |
|---|---|---|---|---|---|
Technical management |
main users |
facilitate adapting developer profiles for different project opportunities |
Heads of Development, COO |
★★★★★ |
user documentation, tutorials |
Team assistants |
main users |
help the technical management achieve their goals |
tbd |
★★★✰✰ |
user documentation, tutorials |
Employee |
occasional users |
facilitate to update and maintain their own profiles |
internal surveys |
★★★★✰ |
tutorials, user documentation |
Developer |
occasional users, contributors |
creating awesome software |
project team |
★★✰✰✰ |
developer documentation, architectureal guidance |
2. Boundary conditions
-
Project language: English (code and documentation)
-
Development environment: IntelliJ IDEA or comparable
-
Module structure: Single module Maven project (can be modularized later if necessary)
-
Version control: Git, trunk-based branch model
-
Testing and quality tools: SonarQube/SonarCloud, ArchUnit, AssertJ
-
Documentation: Asciidoc (PlantUML support) in Arc-42 Canvas
-
Code formatting: spotless, Google Java format
-
Logging: slf4j
-
Infrastructure: onboarding via provided tools, open-source tool landscape
-
Technology specifications: Spring Boot, Lombok
-
Deployment: initially without Docker, later optional
-
Handling secrets: create concept
3. Context delimitation
3.1. Technical context
-
Input: Synthetic data, user personas, AI-based analysis tools
-
Output: Markdown profiles, review approvals, tickets, documentation
3.2. Technical context
-
External services: OpenAI API or comparable
-
Internal tools: Sharepoint/Markdown for collaborative editing
-
Code and documentation standards: Arc-42 Canvas → Architectural decisions must be documented
4. Solution Strategy
-
Best practices and coding guidelines (e.g., no two capital letters in a row, meaningful identifiers)
-
Modularization and loose coupling through use case-driven services and clearly defined domain interfaces
-
Test first and review process (multi-stage, approval required)
-
Password and secrets handling via environment variables
4.1. Micro-Architecture
To address the need for clear separation between business logic and external concerns, we adopt the hexagonal architecture as our fundamental solution strategy. This architecture ensures that core domain logic is isolated from technical details such as user interfaces, databases, messaging, and other external systems. By organizing the application around a central domain model with well-defined ports (interfaces) for interaction, and their implementations that handle communication with the outside world, we achieve several strategic goals:
-
Flexibility: The decoupling of business logic and technical adapters allows for straightforward substitution or addition of external systems (e.g., switching from REST to messaging, or from one database technology to another) without impacting the core domain code.
-
Testability: Business logic can be tested in isolation by providing in-memory or mock adapters, fostering a robust and maintainable test strategy.
-
Maintainability: Clarity of boundaries supports code maintenance, modular evolution, and reduces side-effects during system changes.
-
Adaptability: Adapters can be extended for new protocols or integrations with minimal risk, supporting system growth and future requirements.
In summary, the hexagonal architecture guides our solution strategy by providing a resilient, modular, and evolvable foundation for our system. All dependencies flow inwards to the domain model, with application logic shielded from technology-specific changes by the use of abstract ports and concrete adapters, consistent with the principles of sustainable enterprise software architecture.
5. Building block view
5.1. Package Structure
The codebase uses a package structure designed to emphasize domain concepts, integration boundaries, and interface technologies, supporting a clear, maintainable, and evolvable system architecture. The static package organization is as follows:
-
de.infoteam.profile_assist-
integration-
Contains service-global or framework-specific integration utilities, such as centralized configuration objects.
-
-
domain-
control: Implements the application’s use cases as small, single-purpose classes or services. Each control structure represents an independent business process, enhancing modularity and testability by adhering to the single responsibility principle. This use-case oriented approach helps to achieve a so-called "screaming architecture"—the structure and naming of our control classes make the business capabilities of the system immediately obvious, both to developers and stakeholders. -
entity: Contains domain model entities and aggregates.
-
-
port-
llm-
integration(optional): Integration adapters for LLM-specific functionality. -
control: LLM use cases and orchestration logic, organized in line with domain-centric, use-case granularity. -
entity: LLM domain-specific structures.
-
-
rest-
integration(optional): REST adapters and integration code, e.g., Spring Security setup for access control. -
control: REST interface logic, with each controller mapped to a distinct business use case for clarity and separation. -
entity: Data transfer and resource representation for REST interfaces.
-
-
-
By adhering to use-case based control classes and emphasizing domain-driven terminology and boundaries, this structure exemplifies "screaming architecture," where the organization of application code makes the system’s core domain and primary use cases explicit at a glance. This improves understanding, onboarding, maintenance, and architectural sustainability.
5.2. File Structure
5.2.1. Persona
Personas are stored in JSON format.
It should be equal to the Model structure of the persona information so it’s readable for a JSON parser.
Additional Files/Certificates can be stored in the same directory as the JSON file.
This is documented here:

5.2.2. Call for Bids
Call For Bids are stored in JSON format.
It should be equal to the Model structure of the call for bids information so it’s readable for a JSON parser.
The folder structure is as following:

5.3. Model Structure
5.3.1. Persona
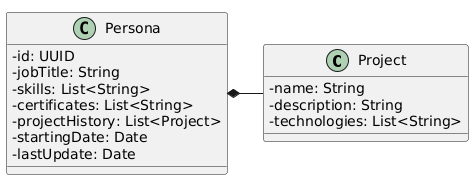
5.3.2. Call for Bids
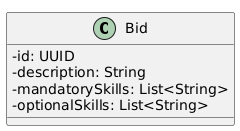
6. Runtime view
-
Profile upload and analysis (onboarding process)
-
Approval and review process for data and profiles
-
Automated tests and quality gates (CI/CD pipeline)
7. Distribution view
-
Single module Maven project (later optional Dockerization)
8. Cross-sectional concepts
-
Logging and monitoring concept (slf4j)
-
Test concept: Branch coverage, AssertJ, ArchUnit rules
-
Code review on demand
-
Code documentation in Asciidoc (with PlantUml support)
-
Nullability and DDD conventions
-
Security concept (handling secrets)
8.1. Nullability and DDD conventions
To reduce NullPointerExceptions, we annotate Java code with JSpecify nullness annotations. This ensures that the nullability of types is clear to both developers and tools, improving code safety, readability, and consistency across the system.
We have decided, that all packages should be declared as @NullMarked by default.
This means that unannotated types are treated as non-null unless explicitly annotated with @Nullable.
Parameters, return types, and fields that may be null must be annotated with @Nullable.
Furthermore, we have decided that we will not use nullness annotations from other sources (e.g. JetBrains).
ArchUnit tests should enforce these rules to ensure compliance and maintain consistency.
9. Architecture decisions
-
Spring Boot as the main framework
-
Focus on testability and maintainability (test coverage, review process)
-
Uniform code formatting and guidelines
-
Hexagonal or DDD-like architecture
10. Quality requirements
-
80% branch coverage as a target
-
Component integration tests mandatory
-
Strict code guidelines and naming conventions
-
No unreviewed data released to the public
11. Risks and technical debt
-
AI integration and data control require clear processes
-
Openness of the project requires careful reviews
12. Glossary
Term |
Description |
Persona |
Template for typical user roles such as full stack, DevOps, etc. |
CallForBids / Call for Bids |
A formal public notice inviting contractors to submit sealed bids. |
Approval process |
Multi-stage review, always with approval from a second person |
Onboarding |
Assistance for new developers, e.g., IDE setup |